

 Kontakt
Kontakt


Analiza CHAID
Drzewa decyzyjne służą do przedstawiania procesu decyzyjnego w sposób graficzny. Są one wykorzystywane do określania przynależności danych obiektów do klas zmiennej zależnej przy użyciu pomiarów zmiennych objaśniających. Drzewa składają się z korzenia i z gałęzi, które prowadzą z tego korzenia do następnych wierzchołków. Wierzchołki, z których wychodzi jedna lub więcej krawędzi, nazywamy węzłami, natomiast pozostałe – liśćmi. Węzeł służy do sprawdzania warunku dotyczącego obserwacji i przyczynia się do podjęcia decyzji dotyczącej wyboru gałęzi prowadzącej do kolejnego wierzchołka.
CHAID oznacza Chi - squared Automatic Interaction Detector (Automatyczny detector interakcji za pomocą chi – kwadrat). Dzięki tej metodzie możliwe jest wybranie z dużego zbioru tych zmiennych , które mają największy wpływ na zmienną objaśnianą (porządkowane są według siły tego wpływu). Celem jest również identyfikacja zmiennych, które najbardziej różnicują dane zjawisko. Podczas podziałów brane są pod uwagę zarówno zmienne ciągłe, porządkowe jak i nominalne, natomiast braki danych mogą być usunięte lub traktowane jako osobna kategoria. Jedyna wada drzew to niestabilność - nawet niewielkie zmiany w próbie mogą prowadzić do sporych różnic w ostatecznej postaci drzewa.
Etapy analizy:
- przygotowanie zmiennych polegające na podziale zmiennych ilościowych na klasy jakościowe,
- w celu sprawdzenia czy dane zmienne różnicują zmienną zależną, dla każdych dwóch kategorii liczony jest test Chi-kwadrat (w przypadku zmiennych nominalnych) lub test F (dla zmiennych ciągłych), wartość testu ocenia zależność między dwoma kategoriami,
- dla każdego predyktora, dla którego zostały już zdefiniowane kategorie obliczana jest wartość Chi-kwadrat lub F oraz wartości p-value dla tych statystyk,
- wybierany jest predyktor, którego p-value jest najmniejsze, gdyż daje ono najistotniejszy podział,
- podział respondentów następuje na podstawie kategorii zmiennej, która została ustalona na początku,
- procedura jest powtarzana dla każdej podgrupy,
- w sytuacji, gdy podgrupy nie da się już podzielić ze względu na małą liczebność, proces jest zatrzymany.
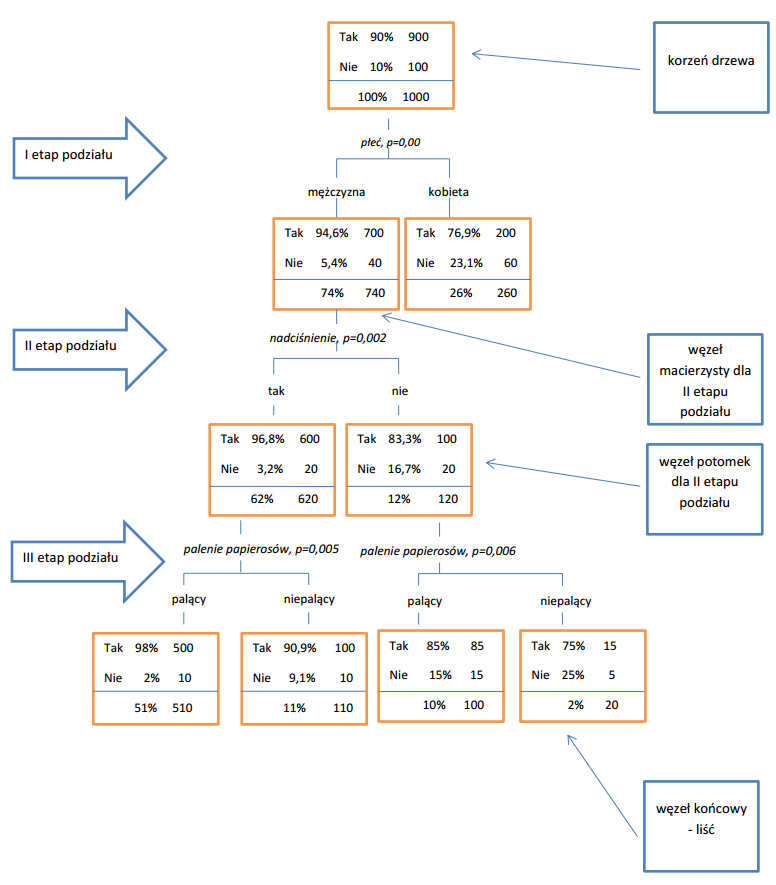
Z poniższego rysunku wynika, iż 90% badanej grupy przeszło w swoim życiu zawał. Informuje o tym rozkład zmiennej zaprezentowany w tzw. korzeniu drzewa. Spośród wszystkich dostępnych zmiennych algorytm wybrał tylko trzy, które różnicują zmienną objaśnianą (zachorowalność na zawał serca). Na tej podstawie drzewo wyróżniają trzy poziomy gałęzi, z czego drugi poziom wyrasta tylko z węzła pierwszego. Najistotniejszą zmienną różnicującą zachorowalność na zawał serca jest płeć. Na tą chorobę cierpi 94,6% mężczyzn oraz 76,9% kobiet. Informują o tym rozkłady procentowe w poszczególnych węzłach drzewa. Jeśli chodzi o grupę mężczyzn, kolejną istotną cechą determinującą zachorowalność jest występujące nadciśnienie. Dalsza interpretacja będzie dotyczyć jedynie mężczyzn. Spośród mężczyzn, którzy cierpią na nadciśnienie, 96,1% przeszło zawał, natomiast spośród mężczyzn, którzy nie mają nadciśnienia, zawał przeszło 83,3% osób. Ostatnią zmienną według której dokonano podziału jest zmienna "palenie papierosów". Z rysunku wynika, że 98% osób płci męskiej, które cierpią na nadciśnienie i palą papierosy oraz 85% mężczyzn niemających problemu z nadciśnieniem, ale palących papierosy, przeszło w swoim życiu zawał serca. Wśród mężczyzn, którzy mają problem z nadciśnieniem, ale nie palą papierosów, zachorowalność na zawał serca wynosi 90,9%, natomiast 75% mężczyzn, których nie dotyczy problem nadciśnienienia i nie palą papierosów, cierpi na tą chorobę. Drzewo CHAID umożliwiło stworzenie wizualnej oceny cech różnicujących zachorowalność na zawał serca.
Czy pacjent przeszedł zawał serca?



 (+48) 666069834
(+48) 666069834
 statystyka@biostat.com.pl
statystyka@biostat.com.pl




